Python爬虫
上个学期使用 JAVA 做了简单的爬虫项目,期间遇到了许多问题,最近在全面学习Python,发现利用Python写爬虫非常方便,现在就把如何利用Python完成爬虫记录下来。
获取静态网页的数据
这个比较简单,数据暴露在页面的源代码中,只需要获取源代码,然后匹配相应的标签就可以获取想要的数据。 上代码:
# 获取煎蛋网的图片 url 保存到本地文件
from pyquery import PyQuery as pq #利用 pyquery 来解析
fileToSave = open('imglinks.txt','w')
for page_number in range(6100,6110): #网页的第6100~6110
url = "http://jandan.net/pic/page-" + str(page_number)
html_content = pq(url)
jpg_container = []
for anchor in html_content('#comments p>img'): #图片的标签路径
anchor = html_content(anchor)
jpg_link = anchor.attr('src') #获取图片标签的 src 属性即为 url
jpg_container.append(jpg_link)
fileToSave.write(jpg_link+'\n')
print(page_number)
fileToSave.close
获取动态网页的数据
现在好多页面的数据不会直接暴露在网页的源代码中,如果需要获取这些网页的数据,需要对网页进行分析。
这里采用嗅探工具对访问页面的整个过程进行分析,我使用的是Burp Suite,它位于应用程序和网站之间,应用程序和网站之间的数据交互它都能捕获。
使用 Chrome 会比较方便,它有一个插件SwitchyOmega(原来的版本是Proxy SwitchySharp),通过该插件新建一个代理服务器,要与Burp Suite设置的相同。
如图所示:
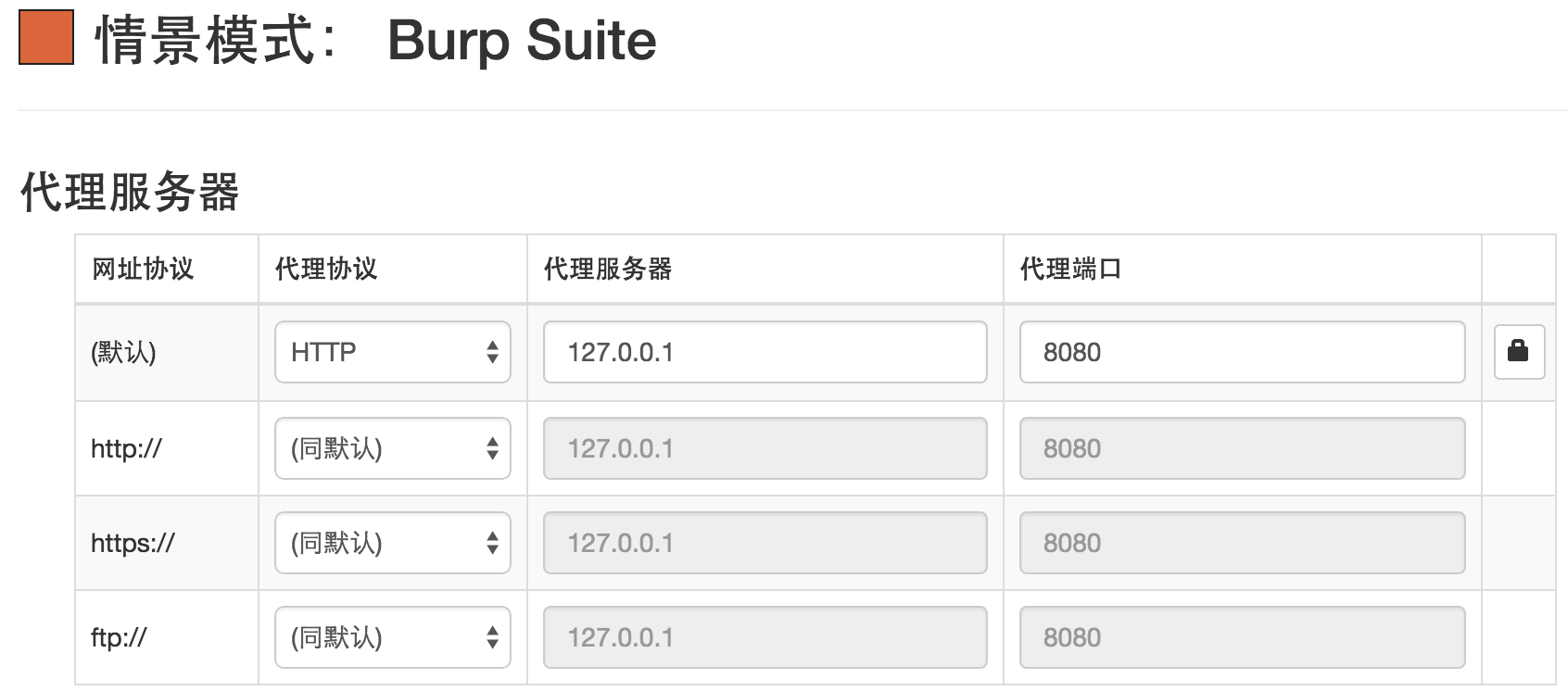
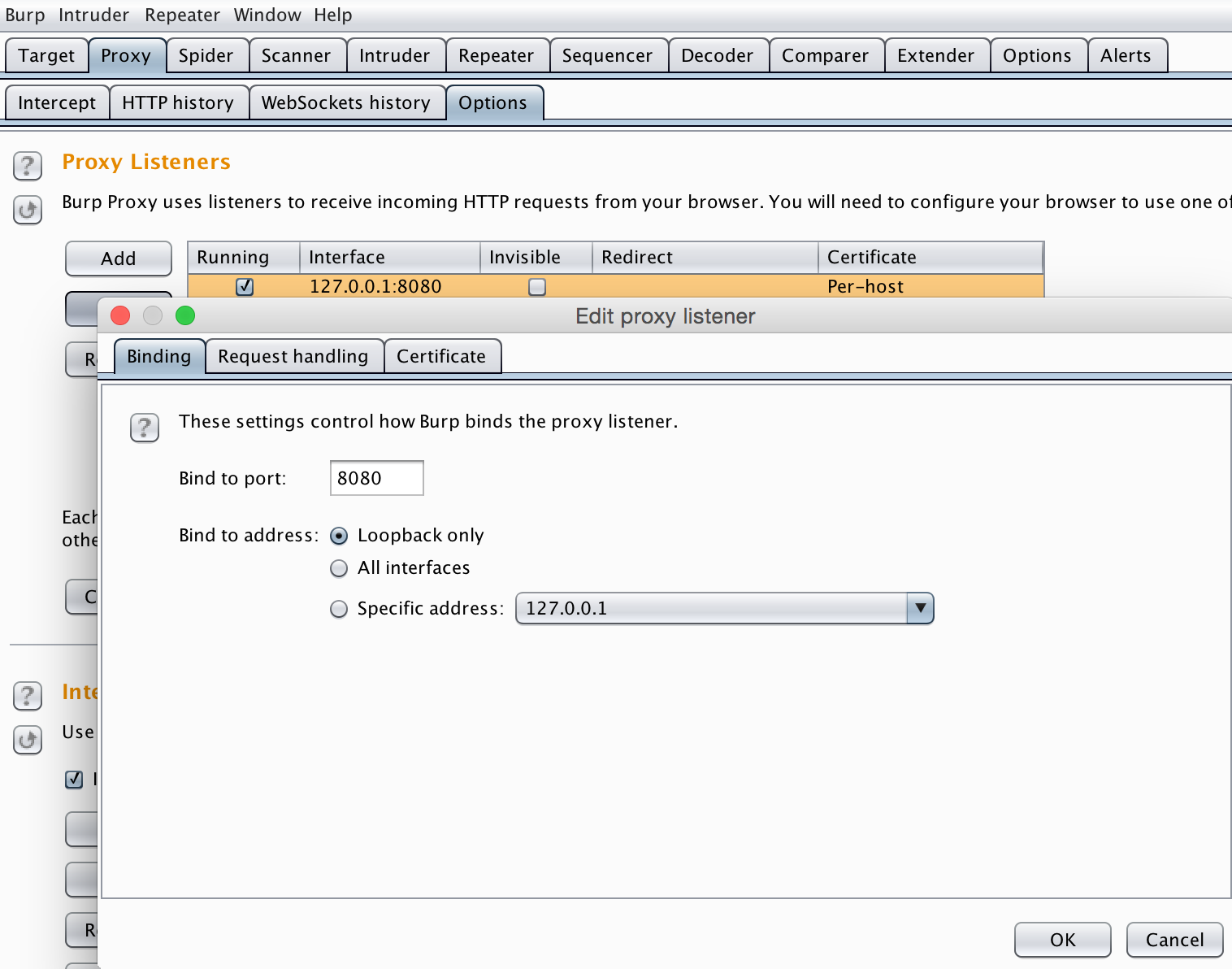
然后将SwitchyOmega(原来的版本是Proxy SwitchySharp)切换到刚配置的 Burp Suite。 这时候访问网页的数据都能捕获到。
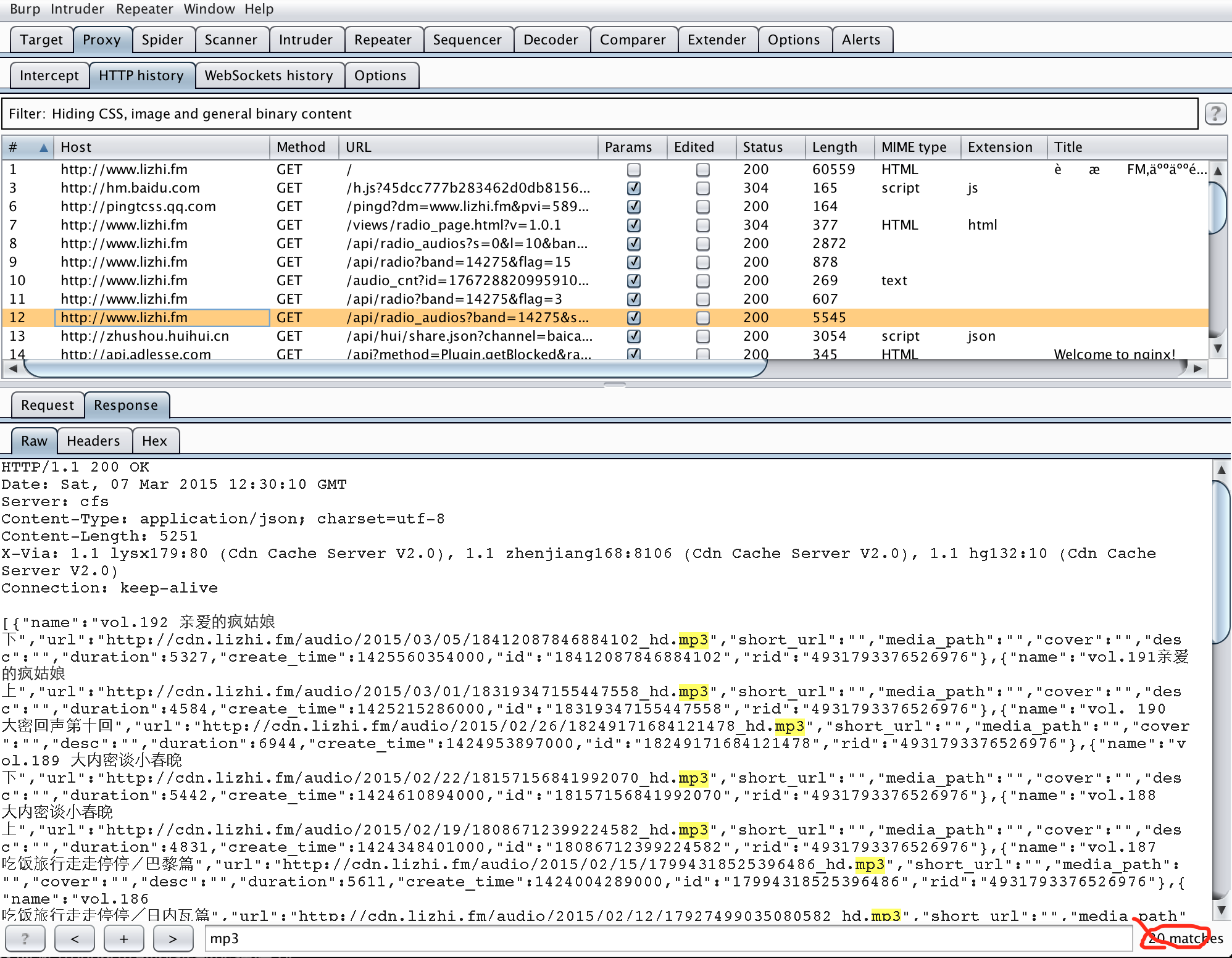
通过尝试可以发现上图即为网站返回的数据,这时查看request部分,即可发现这次访问的 API。
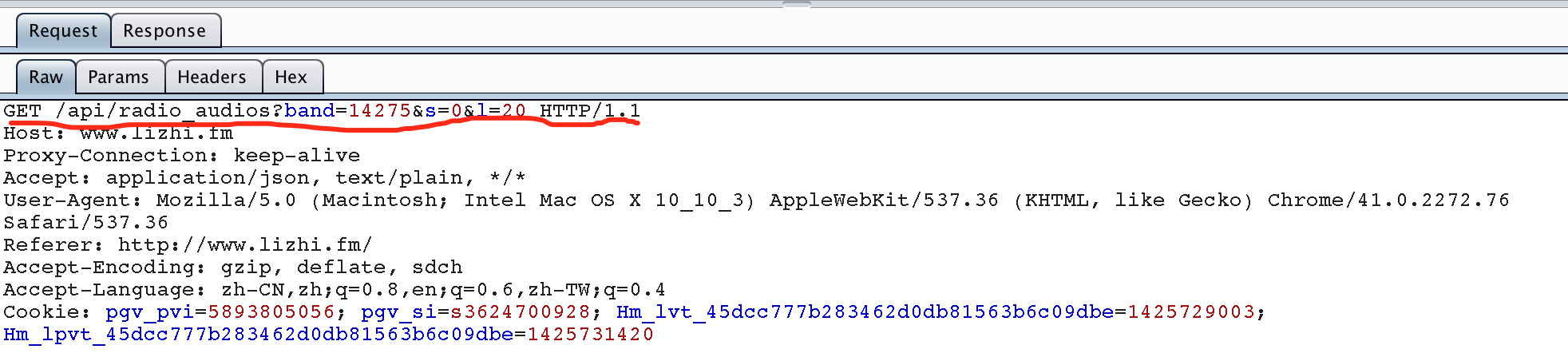
有了 API 就可以使用python来模仿请求了,上代码:
# 获取荔枝 FM 的 mp3
import requests #第三方包
import json
#定义方法,参数分别是 FM的id、mp3的数量
def get_lizhifm_mp3link(radio_id,mp3_number):
file_to_save = open('mp3link.txt','w') #开一个文件,保存数据
r = requests.get('http://www.lizhi.fm/api/radio_audios?band=' + str(radio_id) + '&s=0&l=' + str(mp3_number))
content = r.text
#print(content.encode('utf8'))
result = json.loads(content)
for each_item in result:
#print(each_item['url'])
file_to_save.writelines(each_item['url'] + '\n')
file_to_save.close()
if __name__ == '__main__':
get_lizhifm_mp3link(14275,100)